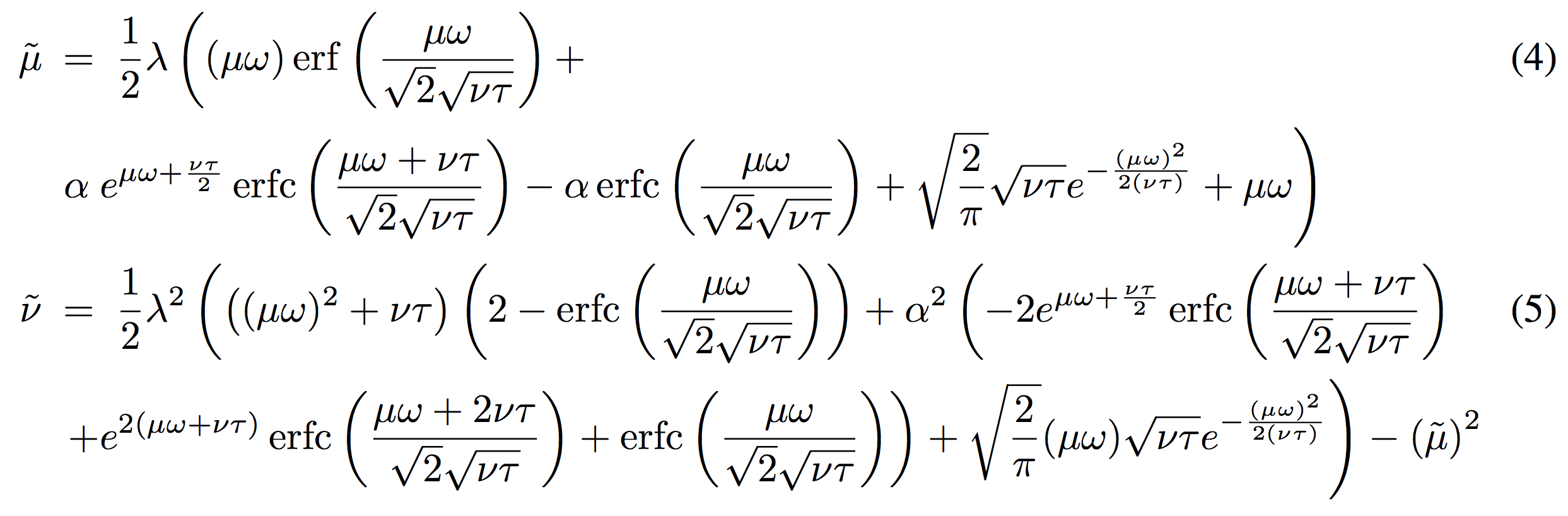Delving Deeper into Convolutional Networks for Learning Video Representations
28 Jun 2017 | Deep Learning Video Representations Action Recognition Video Captioning 모두의 연구소 발표Delving Deeper into Convolutional Networks for Learning Video Representations
- Paper summary
- Delving Deeper into Convolutional Networks for Learning Video Representations Ballas et al. (2016)
- Nicolas Ballas, Li Yao, Chris Pal, and Aaron Courville
1. Introduction
- Video analysis and understanding
- Human action recognition, video retrieval or video captioning
- Previous: hand-crafted and task-specific representations
- Current researches
- CNN: image analysis (good) but NOT use temporal information
- RNN: temporal sequences analysis (good)
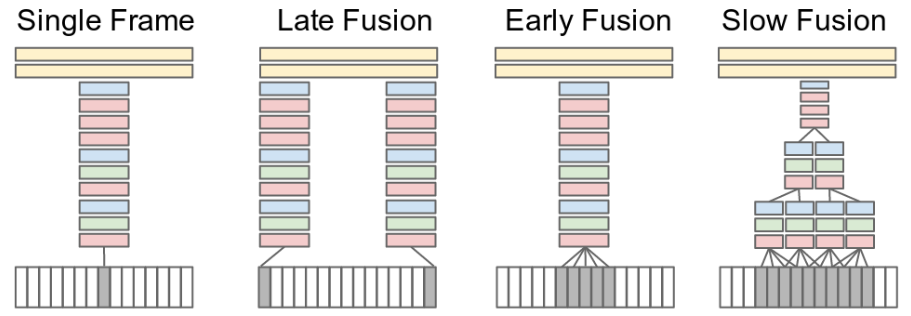
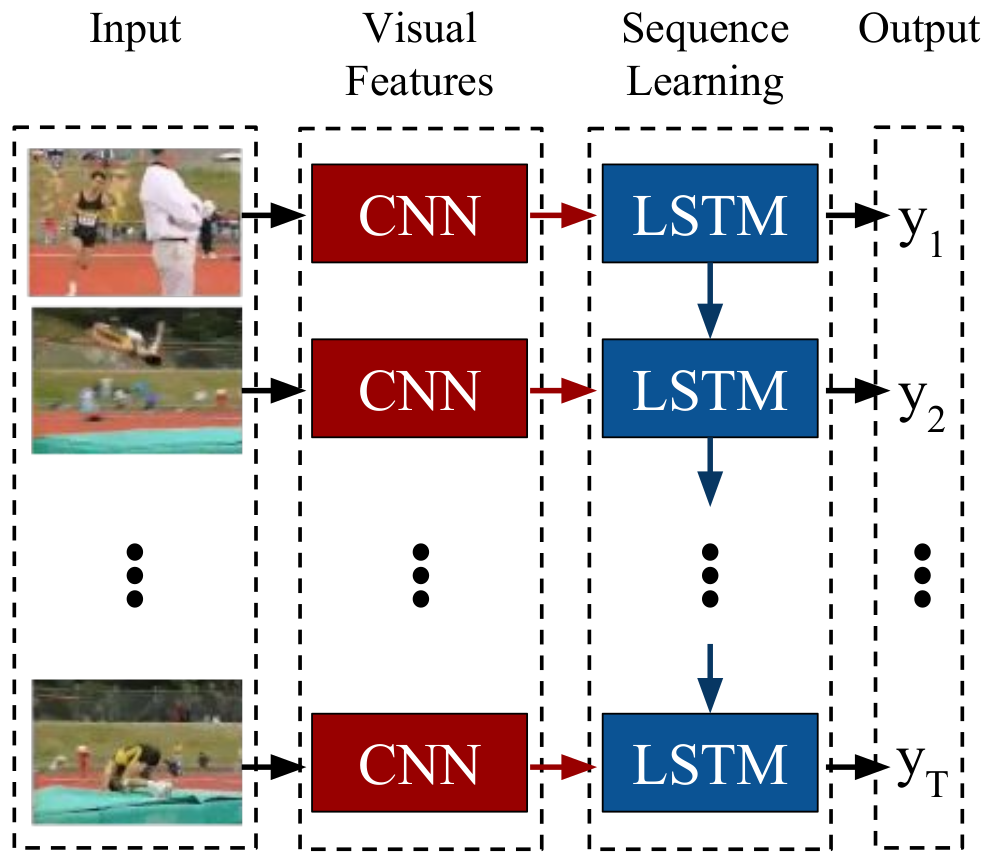
- Recurrent Convolutional Networks (RCN)
- Srivastava et al. (2015) 1; Donahue et al. (2014) 2; Ng et al., 2015 3
- RNN + CNN for learning video representations
Recurrent Convolutional Networks (RCN)
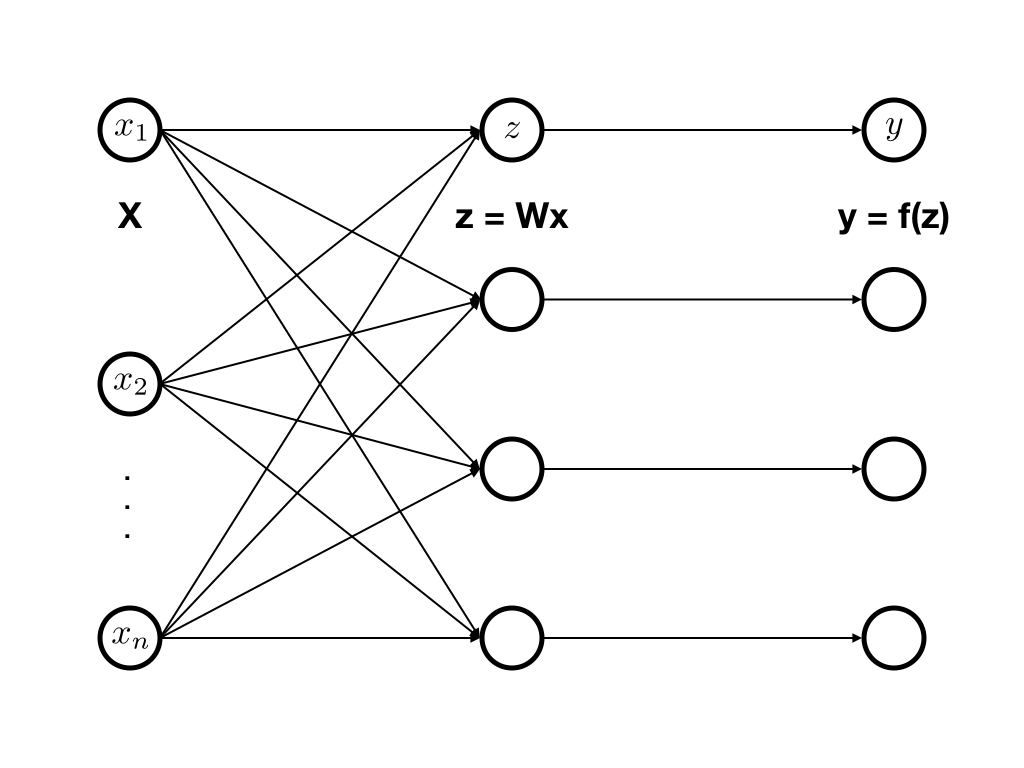
- Basic architecture
- Visual percepts: CNN feature maps
- RNN input: Visual percepts
- Previous works
- High-level visual percepts (only top-layer)
- Drawbacks: local information을 많이 잃어버림
- Drawbacks: frame-to-frame에서 temporal variation이 크지 않음
- Novel architecture
- top-layer + middle-layers
- GRU-RNN:
conv2d opsinstead offc opsin RNN cell
2. Gated Recurrent Unit Networks (GRU)
- Learning phrase representations using rnn encoder-decoder for statistical machine translation, Cho et. al. (2014) 4
- long-term temporal dependency modelling
- ${\bf z}_{t}$: update gate
- ${\bf r}_{t}$: reset gate
- $\odot$: element-wise multiplication
3. Delving Deeper into Convolutional Neural Networks
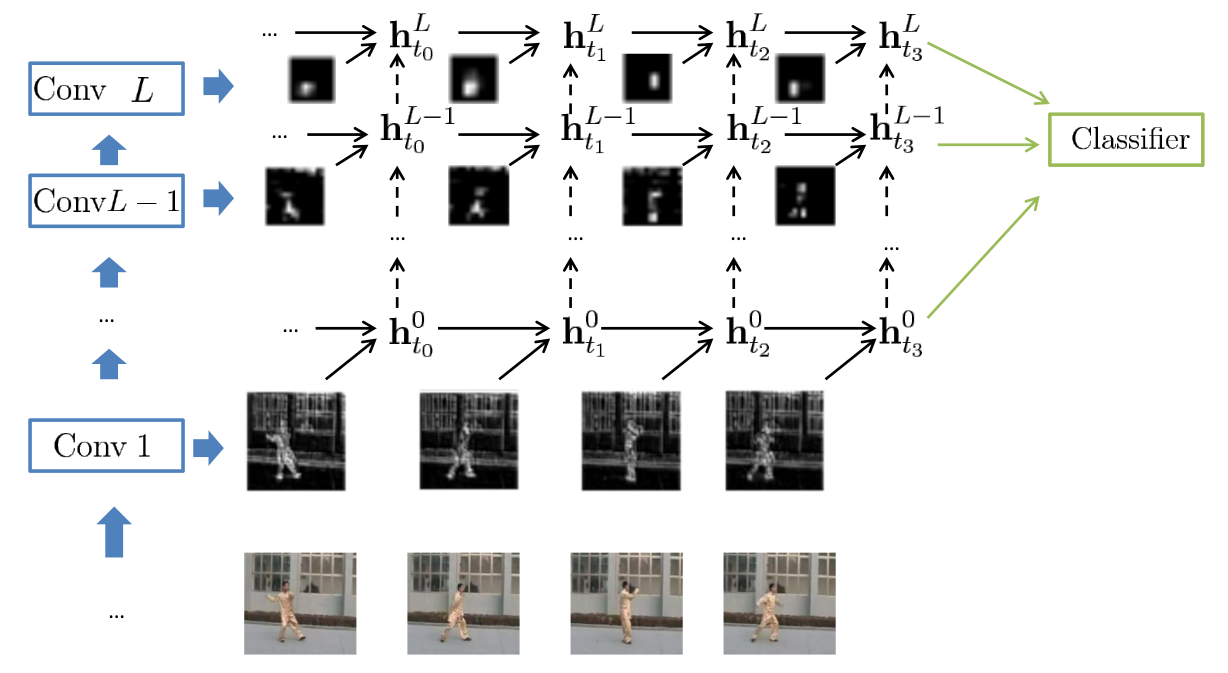
Two GRU-RCN architectures
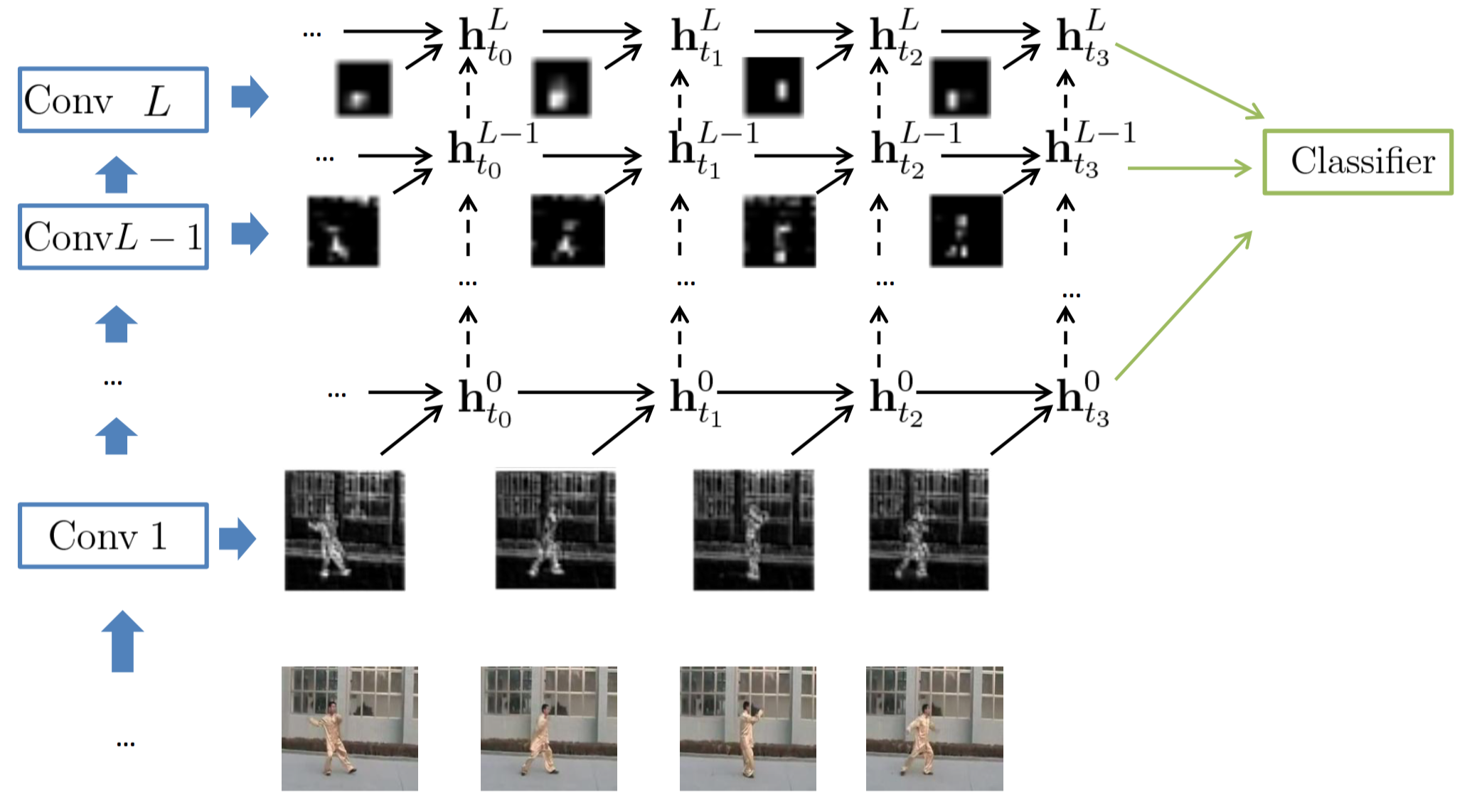
- GRU-RCN (그림에서 위 방향 점선 화살표를 빼면 됨)
- Stacked GRU-RCN (figure)
- $ (\mathbf{x}_{t}^{1}, \cdots, \mathbf{x}_t^{L-1}, \mathbf{x}_t^{L}) $
- $t=1, \cdots, T$
3.1 GRU-RCN
- $ \mathbf{h}_t^l$ $= \phi^l(\mathbf{x}_t^l,$
- $*$:
conv2d ops - 맨 마지막 시점의 hidden들$(\mathbf{h}_{T}^{1}, \cdots, \mathbf{h}_T^{L})$을 가지고 classify
fc ops: conv maps의 특성을 반영하지 못함- conv maps: 다른 위치에서 반복적으로 나타나는 강한 local correlation을 끄집어냄
number of parameters
- number of parameters in GRU
- Size of $\mathbf{W}^{l}$, $\mathbf{W}_{z}^{l}$ and :
- $N_{1} \times N_{2} \times O_{x} \times O_{h}$
- $N$: input spatial size, $O_{x}$: input channels, $O_{h}$: size of hidden node
- Size of $\mathbf{W}^{l}$, $\mathbf{W}_{z}^{l}$ and :
- number of parameters in GRU-RCN
- Size of $\mathbf{W}^{l}$, $\mathbf{W}_{z}^{l}$ and :
- $k_{1} \times k_{2} \times O_{x} \times O_{h}$
- $k$: kernel size; usually $3 \times 3 \ll N_{1} \times N_{2}$
- Size of $\mathbf{W}^{l}$, $\mathbf{W}_{z}^{l}$ and :
3.2 Stacked GRU-RCN
- $\mathbf{h}_{t}^{l}$
- add $\mathbf{h}_{t}^{l-1}$: current time step and previous layer
- $*$:
conv2d ops
4. Related Works
- Large-scale Video Classification with Convolutional Neural Networks Karpathy et al. (2014) 5
- C3D Tran et al. (2015) 6
- 이미지 분류와 달리 비약적인 발전은 없었음
- 오히려 큰 데이터 셋으로 비디오 학습은 힘들다고 함
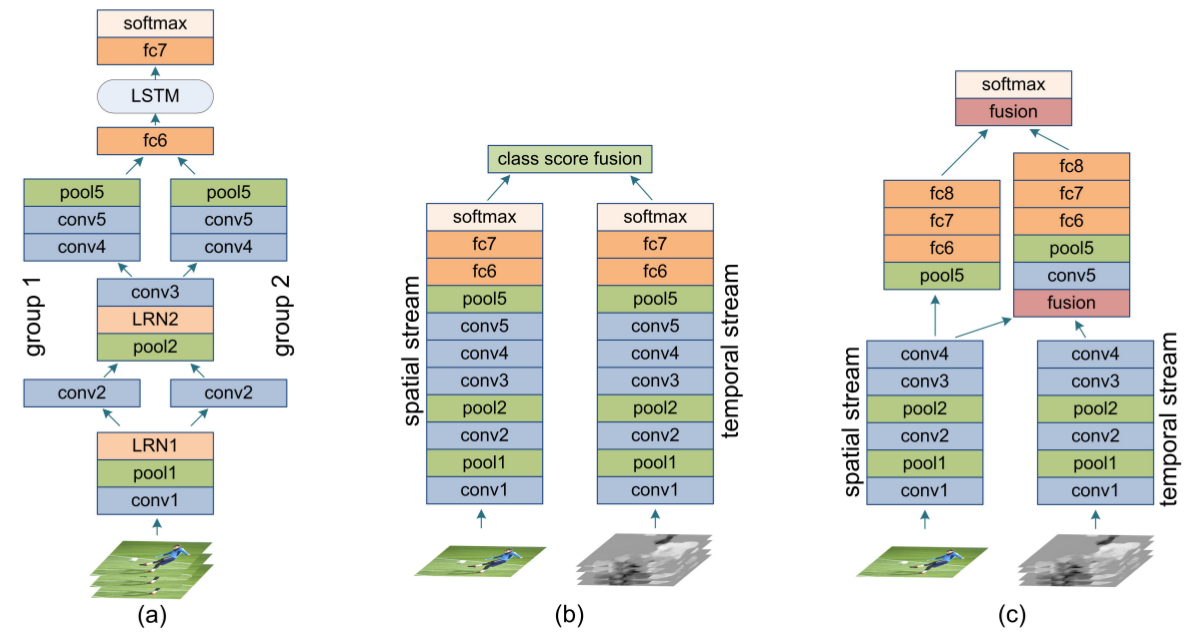
- Two-stream network Simonyan and Zisserman (2014) 7
- RGB color와 optical flow 정보를 각각 인풋으로 넣고 CNN 학습함
- Donahue et al. (2014) 2, Ng et al., 2015 3: Two-stream framework모델의 top layer를 RNN 적용
5. Experiments
5.1 Action Recognition
5.1.1 Model Architecture
- VGG-16: (ImageNet pertained $\rightarrow$ UCF-101로 fine tuning)
- extract 5 feature maps:
pool2,pool3,pool4,pool5, andfc-7 - 위의 feature map들이 RCN 모델의 ${\bf x}_{t}^{l}$ input
- $\mathbf{x}_{t}^{1}$:
pool2 - $\mathbf{x}_{t}^{2}$:
pool3 - $\vdots$
- $\mathbf{x}_{t}^{5}$:
fc-7
- $\mathbf{x}_{t}^{1}$:
- UCF-101 dataset
- 101 action, 13320 youtube video clips
Three RCN architectures
- GRU-RCN
- number of feature maps: 64, 128, 256, 256, 512
average poolingin last time step $T$- ex) Layer 1:
pool2(56 x 56 x 64) $\rightarrow$ (1 x 1 x 64)로 바꿔주기 위함 - 각각을 다섯개의 classifier로 보냄
- 한 classifier는 하나의 hidden representation에만 focus를 맞추고 학습
- 최종 결정은 다섯개의 classifier average로 결정
- dropout prob: 0.7
- Stacked GRU-RCN
- bottom-up connection이 얼마나 중요한지 조사하기 위해 실험
- 아래 layer input의 spatial dimension을 맞추기 위해 max-pooling을 함
- Bi-directional GRU-RCN
- reverse temporal information의 중요성을 체크하기 위해 실험
5.1.2 Model Training and Evaluation
- Follow the two-stream framework
- batch size: 64 videos
- 네가지 사이즈 256, 224, 192, 168 중 하나로 random하게 cropping
- temporal cropping size: 10
- 최종 인풋은 224로 resize, 최종 인풋의 볼륨은 (224 x 224 x 10)
- Maximum log-likelihood
5.1.3 Results

Baseline result
- VGG-16: pre-trained ImageNet and fine tune on the UCF-101
- VGG-16 RNN:
fc-7을 GRU의 input 으로 넣음- GRU cell이
fully connected
- GRU cell이
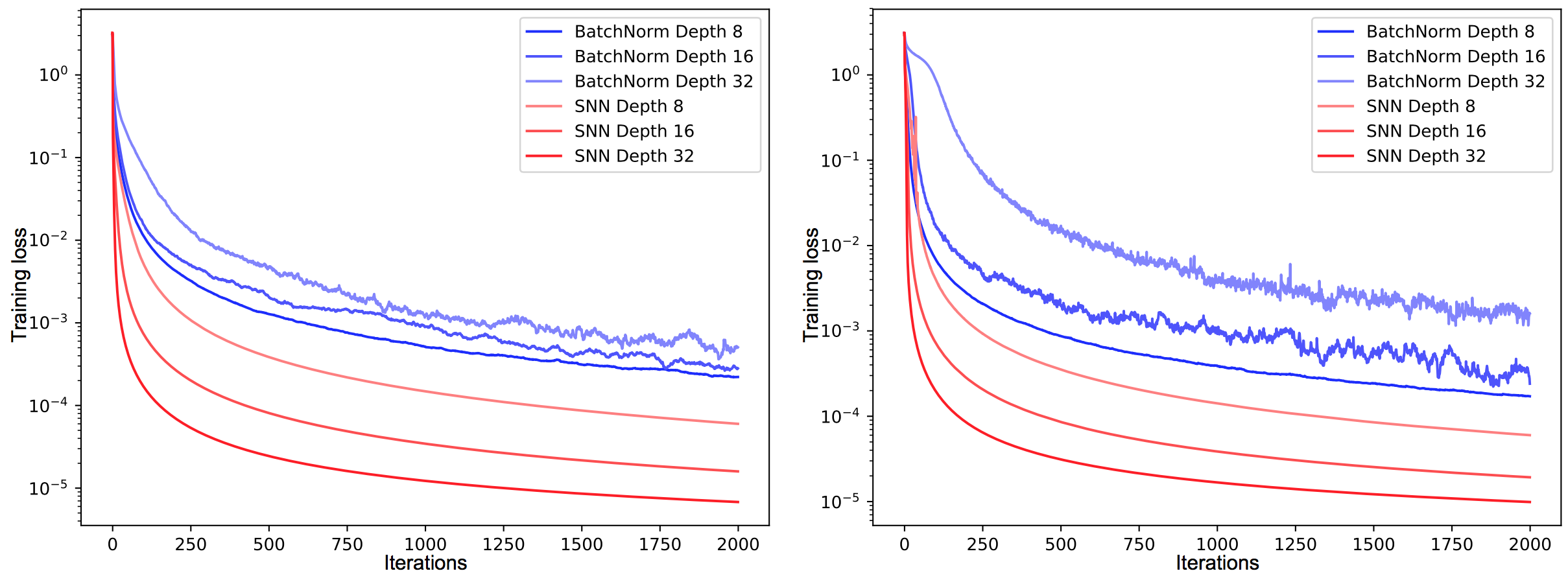
- VGG-16 RNN(78.1) $>$ VGG-16(78.0): slightly improve
- CNN top-layer가 temporal information을 많이 잃어버렸다는 증거
RGB test
- Best: Bi-directional GRU-RCN
- state-of-art
- C3D (Tran et. al.): 85.2
- Karpathy: 65.2
Flow test
- Best: GRU-RCN (85.4 $\rightarrow$ 85.7)
- VGG16이 이미 10장의 연속된 이미지를 가지고 학습하기 때문에 그런 것 같음
RGB + Flow
- Details: Wang et al., (2015b) 8
- 두 모델을 각각 돌리고 weighted linear combination
- baseline: fusion VGG-16: 89.1; state-of-art: 90.9 (Wang)
- Combining Bi-directional GRU-RCN: 90.8
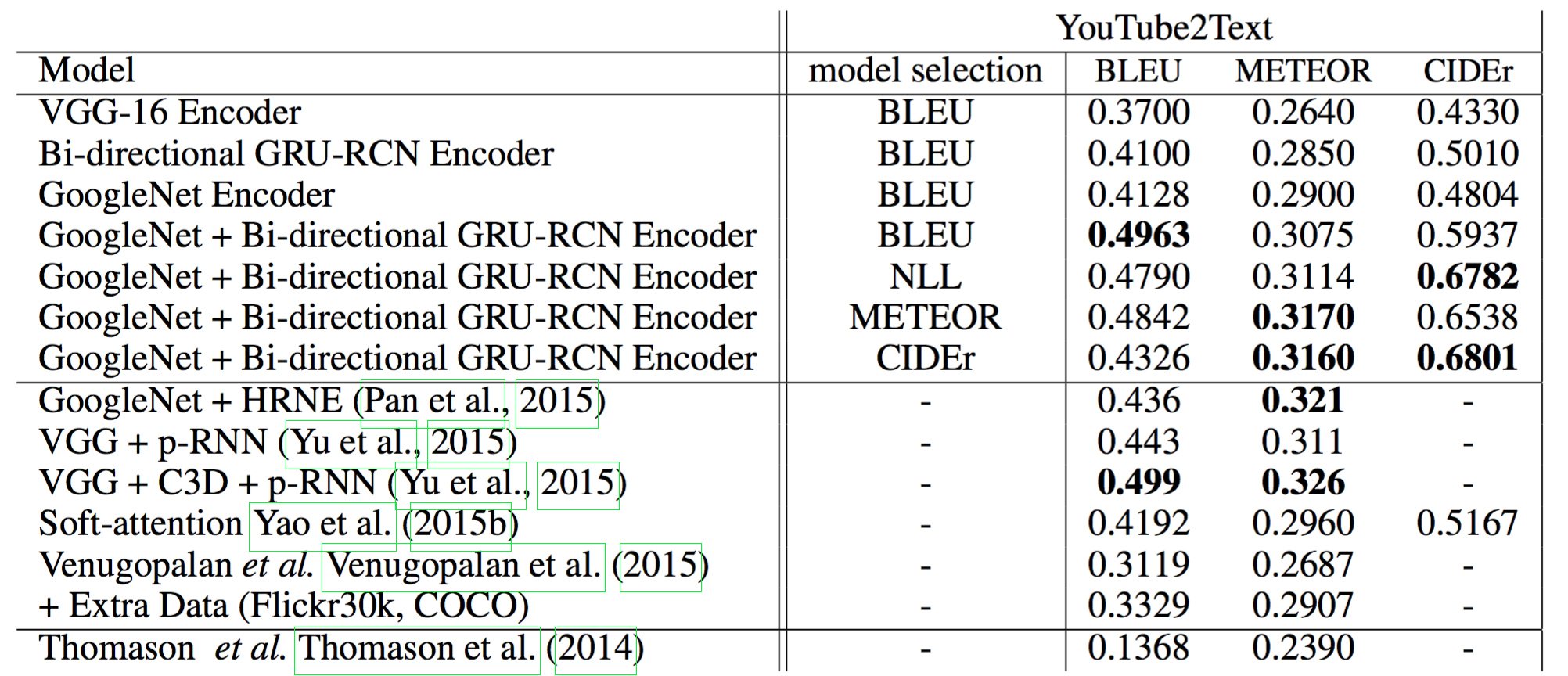
5.2 Video Captioning
5.2.1 Model Specifications
- Data
- YouTube2Text: 1970 video clips with multiple natural language descriptions
- train: 1200, valid: 100, test: 670
- Encoder-decoder framework: Cho et. al. (2014) 4
- Encoder
- K equally-space segments(K=10)
- 10개로 segment를 나누고 각각의 VGG-16에서 fc7 layer를 뽑아냄
- 마지막 time step에서 합치고 (concatenate) 그걸 input 으로 사용
- Decoder: LSTM text-generator with soft-attention, Yao et. al. (2015b) 9
5.2.2 Training
5.2.3 Results
6. Conclusion
- temporal variation을 잘 모델링하기 위해 서로 다른 spatial resolution을 이용
- top layer에 가까우면 discriminative information이 더 높지만 spatial resolution이 떨어짐
- 아래 레이어에 가까우면 그 반대
- VGG-16에서 5개의 layer를 뽑아 멀티 레벨 GRU 적용
Miscellaneous
References
-
Srivastava, N., Mansimov, E., and Salakhutdinov, R. Unsupervised learning of video representations using lstms. In ICML, 2015. ↩
-
Donahue, J., Hendricks, L., Guadarrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., and Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. arXiv preprint arXiv:1411.4389, 2014. ↩ ↩2
-
Ng, Joe Yue-Hei, Hausknecht, Matthew, Vijayanarasimhan, Sudheendra, Vinyals, Oriol, Monga, Rajat, and Toderici, George. Beyond short snippets: Deep networks for video classification. arXiv preprint arXiv:1503.08909, 2015. ↩ ↩2
-
Cho, K., Van Merrie ̈nboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014. ↩ ↩2
-
Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1725–1732, 2014. ↩
-
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional networks. In Proc. Int. Conference on Computer Vision (ICCV), pages 4489–4497, Dec 2015. ↩
-
Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In Proc. Advances in Neural Information Processing Systems (NIPS), pages 568–576, 2014. ↩
-
Wang, Limin, Xiong, Yuanjun, Wang, Zhe, and Qiao, Yu. Towards good practices for very deep two-stream convnets. arXiv preprint arXiv:1507.02159, 2015b. ↩
-
Yao, Li, Torabi, Atousa, Cho, Kyunghyun, Ballas, Nicolas, Pal, Christopher, Larochelle, Hugo, and Courville, Aaron. Describing videos by exploiting temporal structure. In Computer Vision (ICCV), 2015 IEEE International Conference on. IEEE, 2015b. ↩