

Going Deeper into Action Recognition: A Survey
15 Jun 2017 | Action Recognition Deep Learning Survey paperGoing Deeper into Action Recognition: A Survey
- Paper summary
- Going Deeper into Action Recognition: A Survey Herath et al. (2016)
Abstract
- The broad range of applications
- video surveillance
- human-computer interaction
- retail analytics
- user interface design
- learning for robotics
- web-video search and retrieval
- medical diagnosis
- quality-of-life improvement for elderly care
- sports analytics
- Comprehensive review
- handcrafted representations
- deep learning based approaches
Introduction
What is an action?
- Human motions
- from the simplest movement of a limb
- to complex joint movement of a group of limbs and body
- action seems to be hard to define
- Moeslund and Granum (2006) 1; Poppe (2010) 2
- action primitives as “an atomic movement that can be described at the limb level”
- action: a diverse range of movements, from “simple and primitive ones” to “cyclic body movements”
- activity: “a number of subsequent actions, representing a complex movement
- Ex) left leg forward: action primitive of running
- Ex) jumping hurdles: activity performed with the actions starting, running and jumping
- Turaga et al. (2008) 3
- action: “simple motion patterns usually executed by a single person and typically lasting for a very short duration (order of tens of seconds)”
- activity: “a complex sequence of actions performed by several humans who could be interacting with each other in a constrained manner.
- Ex) actions: walking, running, or swimming
- Ex) activity: tow persons shaking hands or a football team scoring a goal
- Wang et al. (2016) 4
- action: “the change of transformation an action brings to the environment”
- Ex) kicking a ball
- action: “the change of transformation an action brings to the environment”
- Authors
- Action: “the most elementary and meaningful interactions” between humans and the environment
- the category of the action: the meaning associated with this interaction
Taxonomy
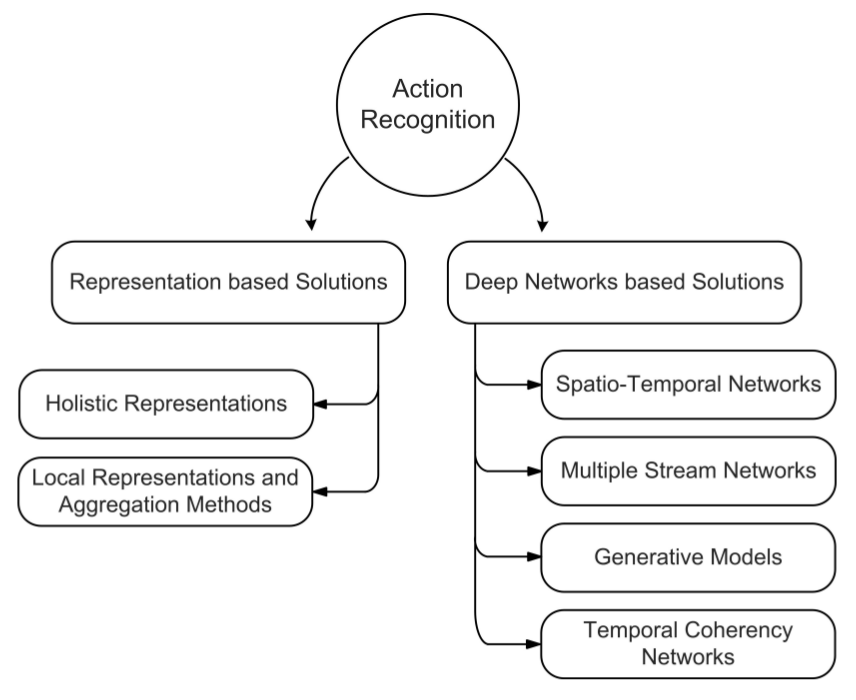
1. Where to start from?
- A good representation
- be easy to compute
- provide description for a sufficiently large class of actions
- reflect the similarity between two like actions
- be robust to various variations (e.g., view-point, illumination)
- Earliest works
- make use of 3D models
- but 3D models is difficult and expensive
- Another solutions without 3D
- Holistic representations
- Local representations
1.1 Holistic representations
- Motion Energy Image (MEI) and Motion History Image (MHI)
- MEI equation
- $ D(x, y, t) $: a binary image sequence representing the detected object pixels

- Spatiotemporal volumes & spatiotemporal surfaces
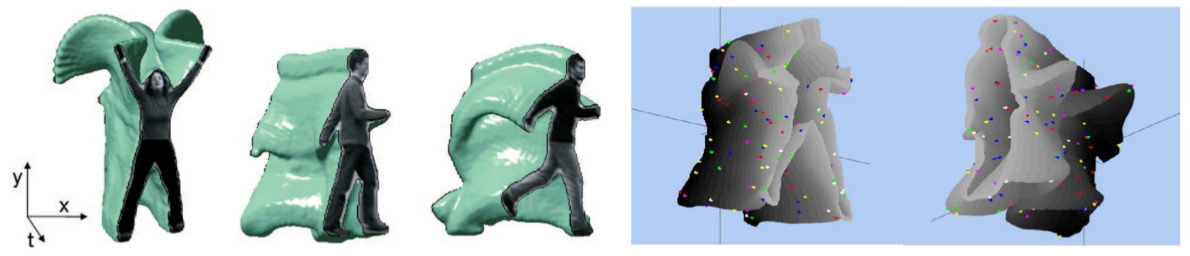
- The holistic approaches are too rigid to capture possible variations of actions (e.g., view point, appearance, occlusions)
- Silhouette based representations are not capable of capturing fine details within the silhouette
2. Local Representation based Approaches
- Pipeline of action recognition using local representation
- interest point detection → local descriptor extraction → aggregation of local descriptors.
2.1 Interest Point Detection
- Space-Time Interest Points (STIPs)
- 3D-Harris detector: extend version of Harris corner detector
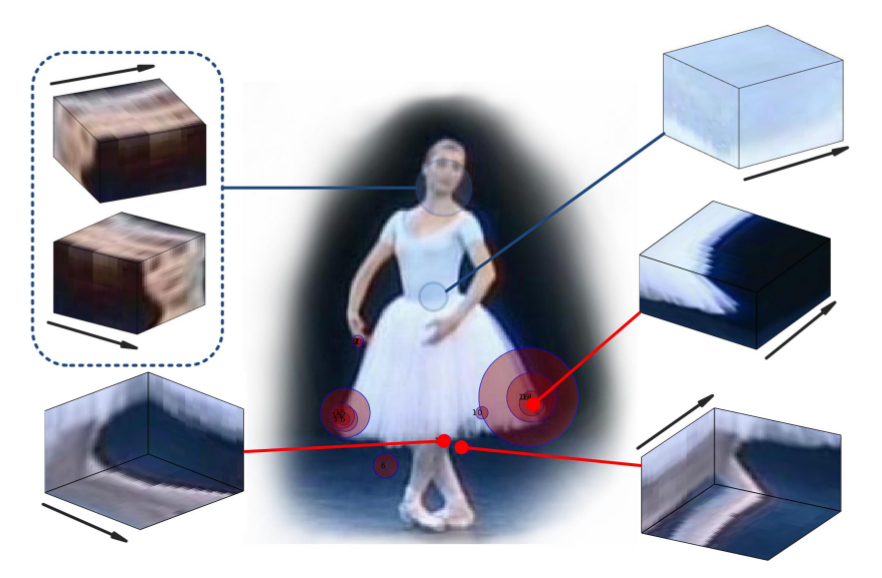
2.2 Local Descriptors
Edge and Motion Descriptors
- HoG3D: extended version of Histogram of Gradient Orientations
- HoF: Histogram of Optical Flow
- Motion Boundary Histogram (HBM)

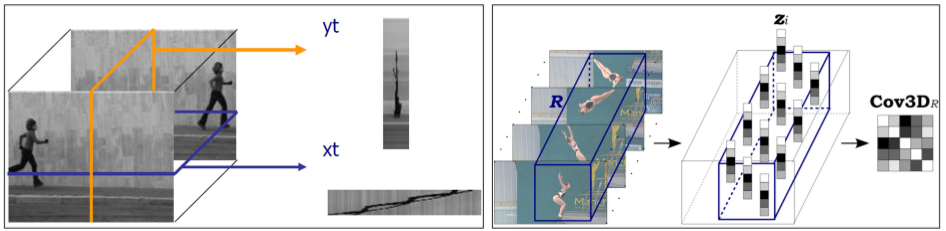
Pixel Pattern Descriptors
- Volume local binary patterns (VLBP)
- Region Covariance Descriptor (RCD)
3. Deep Architectures for Action Recognition
- Four categories
- Spatiotemporal networks
- Multiple stream networks
- Deep generative networks
- Temporal coherency networks
3.1 Spatiotemporal networks
- Filters learned by CNN
- in very first layers: low level features (ex. Gabor-like filters)
- in top layers: high level semantics
- Direct approach
- apply convolution operation with temporal information
- 3D convolution Ji et al. (2013) 5
- 3D kernels: extract features from both spatial and temporal dimensions
- conv3d has fixed temporal domain (ex. fixed 10 frame input)
- it is unclear why a similar assumption should be made across the temporal domain
- Various Fusion Schemes
- Temporal pooling Ng et al. (2015) 6
- Slow fusion Karpathy et al. (2014) 7
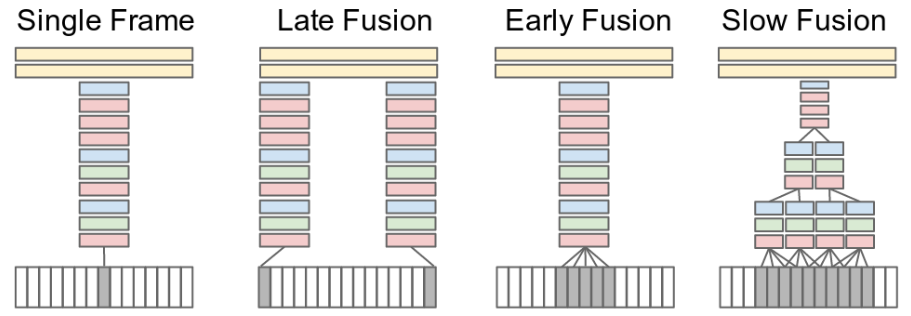
- C3D Tran et al. (2015) 8
- Factorizing conv3d into conv2d and conv1d Sun et al. (2015) 9
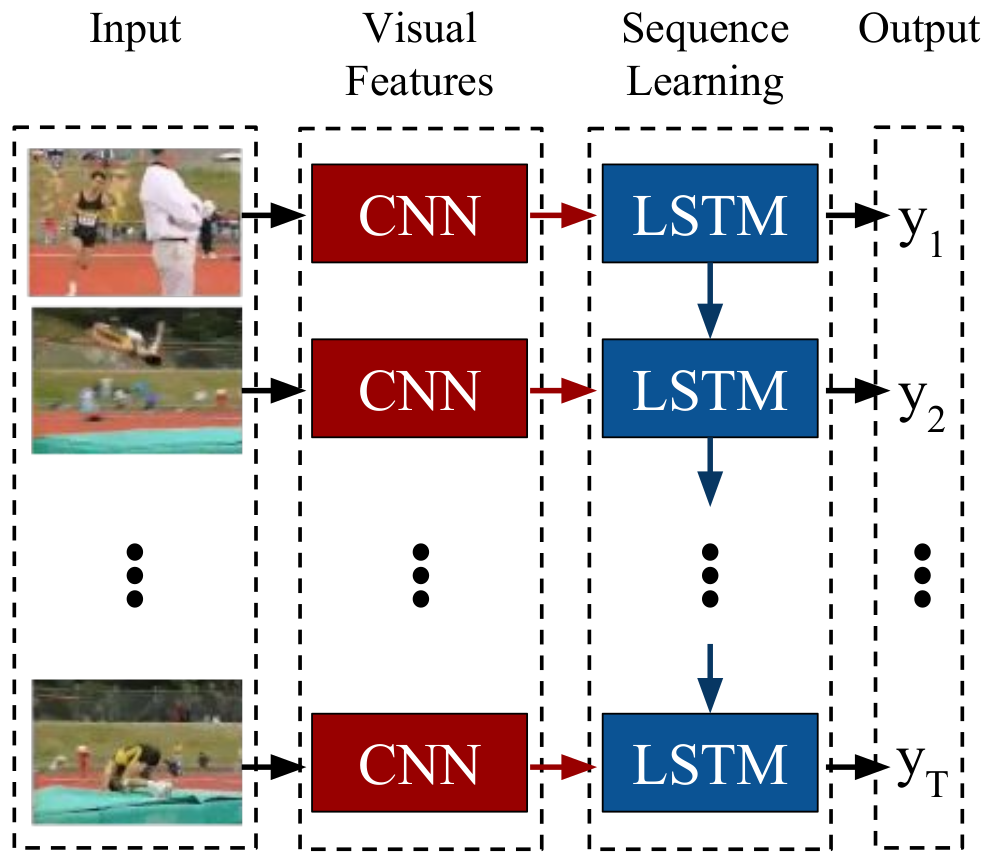
- Recurrent structure
- Long-term Recurrent Convolutional Network Donahue et al. (2015) 10
- Delving (GRU-RCN) Ballas et al. (2016) 11
- above paper is not mentioned in this survey paper
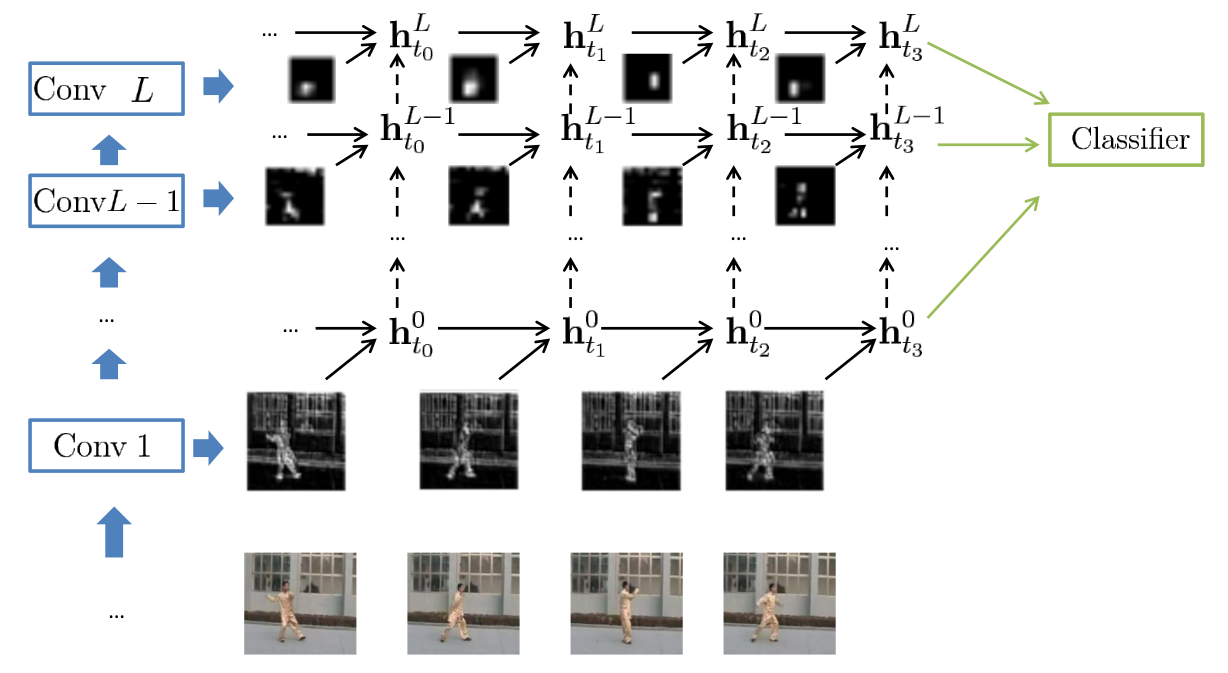
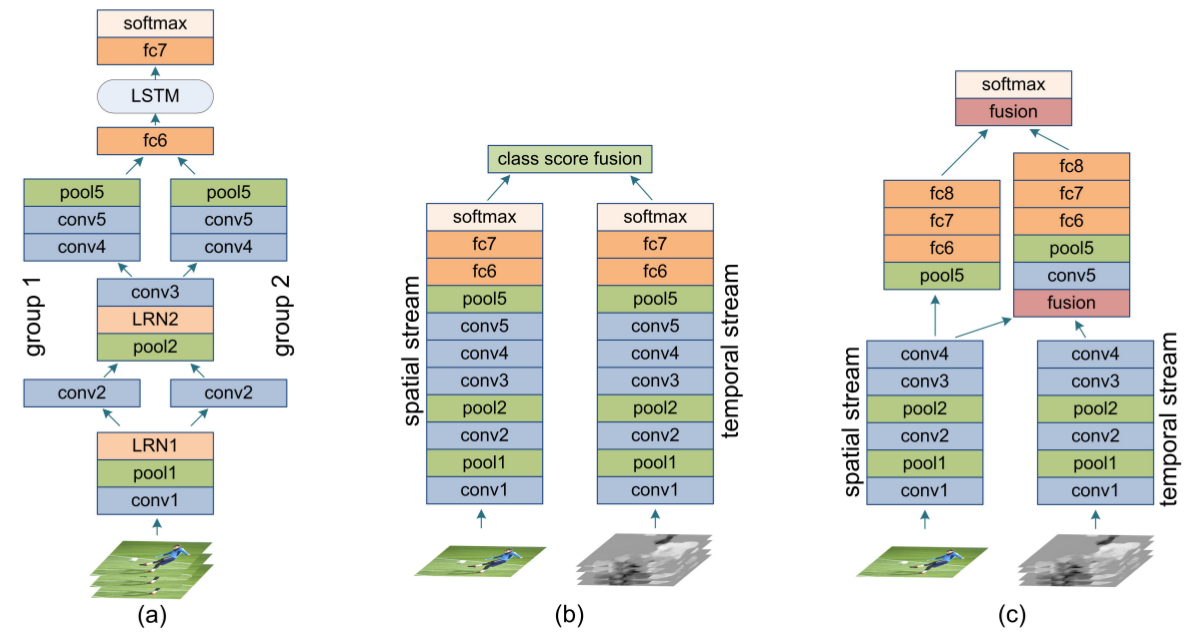
3.2 Multiple Stream Networks
- Fig(b) Two-stream network Simonyan and Zisserman (2014) 12
- Fig(c) Two-stream fusion network Feichtenhofer et al. (2016) 13
3.3 Deep Generative Models
less relevant to my works
3.4 Temporal Coherency Networks
less relevant to my works
4. A Quantitative Analysis
4.1 What is measured by action dataset?
- Comprehensive list of available datasets
| Dataset | Source | No. of Videos | No. of Classes |
|---|---|---|---|
| KTH | Both outdoors and indoors | 600 | 6 |
| Weizmann | Outdoor vid. on still backgrounds | 90 | 10 |
| UCF-Sports | TV sports broadcasts (780x480) | 150 | 10 |
| Hollywood2 | 69 movie clips | 1707 | 12 |
| Olympic Sports | YouTube | 16 | |
| HMDB-51 | YouTube, Movies | 7000 | 51 |
| UCF-50 | YouTube | - | 50 |
| UCF-101 | YouTube | 13320 | 101 |
| Sports-1M | YouTube | 1133158 | 487 |
- The complexity of a datasets
- KTH and Weizmann (low complexity)
- limited camera motion, almost zero background clutter
- scope is limited
- basic actions: walking, running and jumping
- YouTube, movies and TV (ex. HMDB-51, UCF-101)
- camera motion (and shake)
- view-point variations
- resolution inconsistencies
- HMDB-51 and UCF-101 (medium complexity)
- the actions are well cropped in the temporal domain
- NOT well-suited: measuring the performance of action localization
- exist subtle class
- chewing and talking
- playing violin and playing cello
- Hollywood2 and Sports-1M (high complexity)
- view-point/editing complexities
- the action usually occur in a small portion of the clip
- Sports-1M has scenes of spectators and banner adverts
- HMDB-51, UCF-101, Hollywood2 and Sports-1M
- cannot be distinguished by motion clues
- the objects contributed to the actions become important
- Deep learning need to very very much dataset
- training on small and medium size datasets (KTH and Wiezmann) is difficult
- Many researches exploit the pretrained model using Sports-1M dataset
- KTH and Weizmann (low complexity)
4.2 Recognition Results
- column Type: Deep-net based(D), Representation based(R), Fused solution(F)
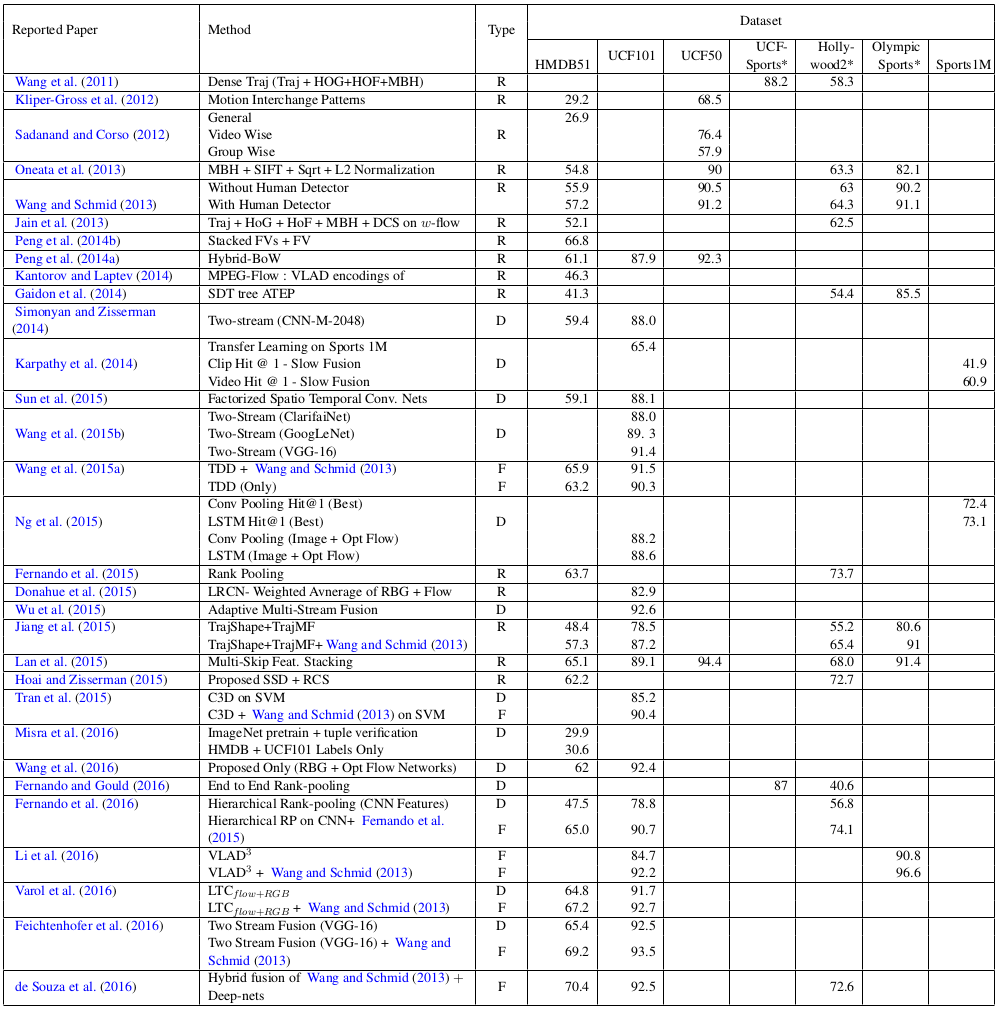
State-of-the-art solutions
- Deep-net solutions
- The spatiotemporal networks
- Two-stream networks
- More rigorous data augmentation
- temporal crops by random clip sampling
- frame skipping
4.3 What algorithmic changes to expect in future?
4.4 Bringing action recognition into life
We must fully understand the following areas in order to apply action recognition in real-life scenarios
- joint detection and recognition from a sequence
- constraining into a refined set of actions instead of big pool of classes
References
-
Thomas B. Moeslund and Erik Granum. A survey of advances in vision-based human motion capture and analysis. Computer Vision and Image Understanding, 104(3):90–127, 2006. ↩
-
Ronald Poppe. A survey on vision-based human action recognition. Image Vision Comput., 28(6): 976–990, 2010. ↩
-
P. Turaga, R. Chellappa, V. S. Subrahmanian, and O. Udrea. Machine recognition of human activities: A survey. IEEE Transactions on Circuits and Systems for Video Technology, 18(11): 1473–1488, 2008. ↩
-
Xiaolong Wang, Ali Farhadi, and Abhinav Gupta. Actions ~ transformations. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2658–2667, 2016. ↩
-
S. Ji, W. Xu, M. Yang, and K. Yu. 3d convolutional neural networks for human action recognition. IEEE Trans. Pattern Analysis and Machine Intelligence, 35(1):221–231, Jan 2013. ISSN 0162-8828. ↩
-
Joe Yue-Hei Ng, M. Hausknecht, S. Vijayanarasimhan, O. Vinyals, R. Monga, and G. Toderici. Beyond short snippets: Deep networks for video classification. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4694–4702, 2015. ↩
-
Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1725–1732, 2014. ↩ ↩2
-
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional networks. In Proc. Int. Conference on Computer Vision (ICCV), pages 4489–4497, Dec 2015. ↩ ↩2
-
L. Sun, K. Jia, D. Y. Yeung, and B. E. Shi. Human action recognition using factorized spatiotemporal convolutional networks. In Proc. Int. Conference on Computer Vision (ICCV), pages 4597–4605, Dec 2015. ↩
-
Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional networks for visual recognition and description. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2625–2634, 2015. ↩
-
Nicolas Ballas, Li Yao, Chris Pal, Aaron Courville. Delving deeper into convolutional networks for learning video representations. arXiv:1511.06432, 2016. ↩
-
Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In Proc. Advances in Neural Information Processing Systems (NIPS), pages 568–576, 2014. ↩ ↩2
-
Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Convolutional two-stream network fusion for video action recognition. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1933–1941, 6 2016. ↩ ↩2
-
Gül Varol, Ivan Laptev, and Cordelia Schmid. Long-term Temporal Convolutions for Action Recognition. arXiv:1604.04494, 2016. ↩
Comments